New research could improve prediction of financial risks

A bold new idea that challenges traditional approaches to statistics could help close the gap between predictive models and the truth.

The challenge that analytics professionals and statisticians have always faced is that models and analytics only serve as an approximation to the truth. This makes it difficult to predict unknown outcomes, such as financial returns in the context of investments.
Currently, statisticians and analytics specialists formulate an approximating model that mimics the data as much as possible. The model offers predictions on future unknowns, but we can never know whether or not that model is right due to extraneous variables and their complex interactions with the outcome of interest.
As a result, businesses and investors make decisions without a certain picture of future events and associated risks.
Now, Melbourne Business School Associate Professor of Statistics And Econometrics Ole Maneesoonthorn and co-authors Professor Gael Martin, Associate Professor David Frazier and Dr Ruben Laoiza-Maya from Monash University, along with Dr Andres Ramirez-Hassan of EAFIT University in Colombia, have posed a new way forward.
The group's paper Optimal probabilistic forecasts: When do they work? published in the Jan-March 2022 edition of International Journal of Forecasting questions the search for the "perfect" model and focuses on practical outcomes instead.
The predictive gap
In this diagram, you can see how the gap between what is known and unknown affects analysts trying to make predictions:
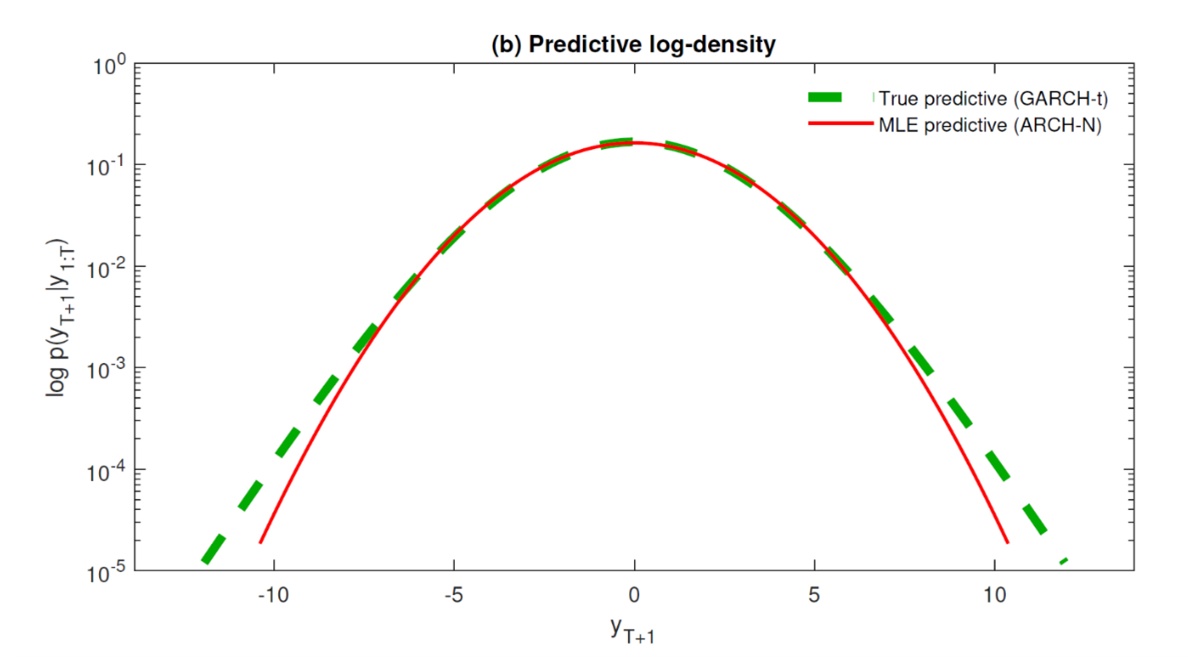
The horizontal axis represents possible values of the data, while the vertical axis represents the likelihood of the corresponding value on the horizontal axis (predictive density). If the green curve is the "truth" and the red curve the predictive model, you can see that while the two curves match for the most part, there are gaps on the far left and right where the truth and the model differ greatly.
Differences on the left of the diagram, where the model in red underestimates the downside risk, could lead to catastrophic losses on financial returns. If investors wish to manage this risk more effectively, it is in their interest to narrow the gap between the truth and the model in the left tail region.
The solution
To solve this problem, it's possible to disregard the predictive curve as a whole and simply focus on the areas that investors are interested in. For example, if investors are looking to manage the downside risk of their investments and minimise the potential downfall of their portfolio value, they will want to focus on the left tail only:

By calibrating the predictive distribution to the region of interest, as shown by the blue line in the diagram, the predictive model is much closer to the truth. While the blue and red lines come from the same model, they are calibrated differently to create a predictive curve optimal to a specific feature.
"For investors, being able to close the gap between the truth and the model can make a massive difference to their estimate of downside risks and the consequent actions required to mitigate them," says Associate Professor Maneesoonthorn.
This approach goes against conventional thinking in statistics, where 'goodness of fit' is viewed as fitting the model to all regions of the data. Instead, to make predictions more useful and applicable, this research advocates that the model should be calibrated to the features that are key to the business problem at hand. This means that incorrect models can be useful, as long as they are compatible with the problem.
Associate Professor Maneesoonthorn and her co-authors found that analysts would be able to close this predictive gap as long as the model is flexible enough to capture the desired feature of the predictive distribution.
In addition, the statistical scoring rule used to calibrate the model must be able to measure the feature of the predictive distribution of interest. This means that incorrect models can be useful, as long as they are compatible with the problem.
Practical relevance in risk management
In an investment context, this could lead to more accurate predictions which would reduce exposure to extreme downside events. It could also provide more accurate predictions in other business areas where it is useful to plan for extreme events, such as operations or supply chain management.
One specific example is in the prediction of value-at-risk (VaR). The VaR is a measure of downside risk that financial institutions rely on to determine their capital allocation, in order to provide a buffer against catastrophic loss.
Since the capital allocation of major financial institutions is constantly monitored by the Australian Prudential Regulation Authority (APRA), it is crucial that the VaR predictions are prudent. However, overly prudent predictions result in a larger fund being set aside that could be used more efficiently in profit-generating functions.
The statistical scoring rule that focuses on the prediction of the percentiles, known as the quantile score, measures the accuracy of the VaR predictions by penalising under-prediction of risks more heavily than over-prediction, and is a theoretically sound metric.
By calibrating a potentially incorrect model using the quantile score, rather than an overall goodness of fit criteria, financial institutions can achieve a more accurate prediction of VaR that strikes a balance between regulatory compliance and efficient resource allocation.
The key takeaway
The outcome of this research questions the quest to search for a 'perfect' model based on the overall goodness of fit criteria. Rather, it brings to the forefront the famous message from George Box that "all models are wrong, but some are useful".
As long as the users have a deep understanding of the problem, and a ready statistical toolset that allows the mapping of the model to the problem, they can produce an accurate prediction of the truth from an incorrect, but flexible, model.
To read the full research paper, visit Optimal probabilistic forecasts: When do they work?
For more analytics information and research, visit our Centre for Business Analytics page.
To find out more about studying at Melbourne Business School, visit our Degree Programs and Short Courses pages, or learn about our range of services For Organisations.

